This week we will be looking into the K'th Smallest Element problem. This week's lab gives us a break from implementing data types, allowing us to look into some sorting algorithms. The sorting algorithm we will be discussing is the Quick Sort algorithm. As always, feel free to leave a comment below and now lets get right into it.
The K'th Smallest Element Problem
Given an array and a value of K, we need to find the K'th smallest element within the array. An example would be if I have a K = 4, then I need to find the 4th smallest element within the array. The solution to this problem would be to sort the array in ascending order and return the K'th element in that array (since it is our K'th smallest element).
However, the run time of this solution will be slow because we are doing a complete sort before returning the K'th smallest value in the array. We can speed this up by not doing a complete sort. We will see this in the implementation section. For now lets get into what Quick Sort is, since we are going to use it to solve this problem.
What is Quick Sort?
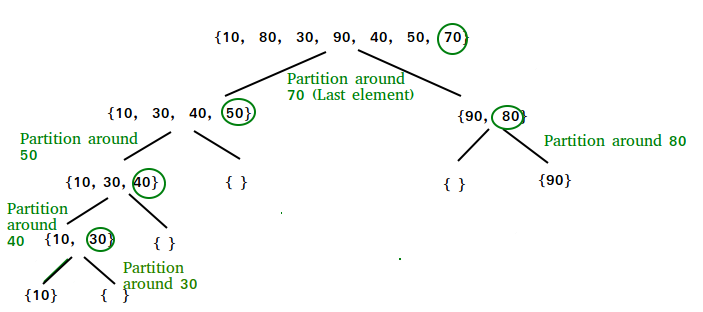
Quick Sort is a sorting method where we choose a number call a pivot, and we split the array of elements into two sub arrays; the left sub array containing elements < pivot and the right sub array containing elements > pivot.
 |
| Quick Sort Visualized |
The act of splitting a single array into two sub arrays in quick sort is called partitioning. The idea behind quick sort is that it is a recursive sorting function. Each quick sort calls results in one call to a partition function, and two more quick sort calls; each one address the left and right sub arrays we created. With each recursive call, we get smaller and smaller sub arrays but also getting closer and closer to a sorted array. Once all the recursive calls return back to the very first quick sort call, we get a sorted array.
Now, there are different ways you can go about partitioning the given array. The method we are going to be using is called the Lomuto Partitioning Scheme, and it is considered to be one of the simplest partitioning methods out there for quick sort.
What is the Lomuto Partitioning Scheme?
The Lomuto Partitioning Scheme starts out with a pivot, a cursor, and a scanner. Our cursor and scanner both start on the left side of a given array, with the scanner moving from the left side to the right side of the array. When the scanner finds a value less than the pivot, it will swap its position with that of the element at the cursor. After the swap, the cursor moves one index up and the scanner keeps moving along the array. After the scanner is done traversing the array, we do a final swap of the element located at the cursor with our pivot.
The idea behind this method is that we create the two sub arrays as mentioned before. The final swap in the end makes sure that our pivot is in a spot where the elements on its left is less than the pivot and the elements on its right is greater than the pivot.
Here is a nice video that does a pretty good job at explaining and showing what the Lomuto Partitioning Scheme is and how it behaves:
The Implementation
This lab we are going to implement three different functions; one will be our partitioning function (we will call partition()) while the other two will be used to find the K'th smallest element (both will be called find_kth_least() but each have different parameters.
Our partition() function will take in three parameters: a vector, and a start and end input. We have a start and end parameter because of the two sub arrays created with every call to the partition function. The partition() function will be an implementation of the Lomuto Partitioning Scheme. The only difference is that the pivot will be the element in the middle of each sub array (meaning (start + end) / 2) instead of the right most element of the sub array as seen with typical implementations of the Lomuto Partitioning Scheme. However, to keep our partition() inline with the typical Lomuto Partitioning Scheme, we will swap the location of our pivot with the element at the right of the sub array.
Now for our two find_kth_least() functions. One of them will be considered as our "public API" function, which takes in a vector and a k value. Within this "public API" function, it will filter the inputs and then make a call to our second find_kth_least() function. This second find_kth_least() function utilizes recursion to determine what the K'th smallest element is in the array.
Our recursive find_kth_least() function takes in four parameters, a vector, a start value, an end value, and a k value. Within our recursive find_kth_least(), we first check that a valid sub array was passed in by checking that our start value is less than or equal to our end value. From there, we call our partition() function, which will return the location of the pivot. If the location of the pivot is equal to k, then we found our kth smallest element. Otherwise, we see if the location of the pivot is bigger or smaller than k, which determines what the next recursive call will do.
The reason we want our pivot to be in the kth index of the array is because of the properties of the pivot. All the elements on the left of the pivot is less than the pivot itself. By having the pivot be in the kth location of the array, it tells us that it is the kth smallest element of the entire array without sorting the entire array.
Our partition() function will take in three parameters: a vector, and a start and end input. We have a start and end parameter because of the two sub arrays created with every call to the partition function. The partition() function will be an implementation of the Lomuto Partitioning Scheme. The only difference is that the pivot will be the element in the middle of each sub array (meaning (start + end) / 2) instead of the right most element of the sub array as seen with typical implementations of the Lomuto Partitioning Scheme. However, to keep our partition() inline with the typical Lomuto Partitioning Scheme, we will swap the location of our pivot with the element at the right of the sub array.
Now for our two find_kth_least() functions. One of them will be considered as our "public API" function, which takes in a vector and a k value. Within this "public API" function, it will filter the inputs and then make a call to our second find_kth_least() function. This second find_kth_least() function utilizes recursion to determine what the K'th smallest element is in the array.
Our recursive find_kth_least() function takes in four parameters, a vector, a start value, an end value, and a k value. Within our recursive find_kth_least(), we first check that a valid sub array was passed in by checking that our start value is less than or equal to our end value. From there, we call our partition() function, which will return the location of the pivot. If the location of the pivot is equal to k, then we found our kth smallest element. Otherwise, we see if the location of the pivot is bigger or smaller than k, which determines what the next recursive call will do.
The reason we want our pivot to be in the kth index of the array is because of the properties of the pivot. All the elements on the left of the pivot is less than the pivot itself. By having the pivot be in the kth location of the array, it tells us that it is the kth smallest element of the entire array without sorting the entire array.
Lab Questions
Q: Suppose you want to calculate the median of a given array of integers, how would you use your pivoting strategy to do it?
A: To calculate the median of a given array of integers, I would probably partition the array until the location of the pivot is in the middle of the given array. The reason being that the median of a list of numbers can be seen as a pivot, since the numbers to the left of the median is smaller than the median and everything to the right of the median is bigger than the median. So, we just need to partition our array until the location of the pivot is in the middle of the array.
Q: Does your strategy yield the k smallest elements or the kth smallest element?
A: This strategy yields both the k smallest element and the K'th smallest element. The K'th smallest element, as said before, is a pivot whose location is kth index of the array. Everything to the left of that pivot is smaller than the pivot itself, meaning they too are the k smallest elements in the array.
Q: We saw that this algorithm is O(N) in the number of elements. Can you do better (meaning sub-linear)? Why or why not?
A: I would say that is it not possible to have an algorithm that can do this with a sub-linear time complexity. The reason I have at this moment is is because of our partition() function, which requires a linear traversal of the entire sub array when partitioning, even though the sub arrays themselves get smaller and smaller by some amount.
Q: Since sorting solves the problem in O(N log N) time, your algorithm probably doesn't sort the input (otherwise you can get a sub-log-linear sort algorithm, right)? What is the trade-off? What are you giving up to get the run-time advantage? Looking at this from the other direction, ask what more a sorting algorithm does that goes unused by you (and is thus safe to omit)? What is the time complexity of just this "omitted" operation in a full fledged sort?
A: I would say the trade-off of not doing a complete sort to increase speed is a unsorted array. Our algorithm at the moment will return the K'th smallest element of the array and a partially sorted array as well (since our vector parameters are actually references). The draw back of this is that we could be completing two tasks at the same time, finding a K'th smallest element and sorting the array. If we were to find another K'th smallest element on the same array while it is partially sorted, it will take more time than finding another K'th smallest element on the same array when it is completely sorted.
Q: How can you get the k smallest elements in the array? What is the time complexity of that procedure? What if you wanted these elements in sorted order?
A: With our current implementation, to find the k smallest elements in an array you would have to find the K'th smallest element in the array (as discussed in the second question of this list). The time complexity of this procedure would be around the same as our current implementation of find_kth_least(). If you wanted these elements in sorted order, the easy way would just to sort those elements only; however, it could affect the overall run time.
Q: Why is it important to make sure that Quicksort does not degrade to O(n^2) on an array of identical values?
A: It is important to make sure that Quicksort does not degrade to O(n^2) on an array of identical values because we are wasting time and resources on an array that is technically already sorted. We can figure out if an array is filled with the same value by doing a quick O(n) traversal check before starting Quicksort.
Q: Why is it important to make sure that Quicksort does not degrade to O(n^2) on an array of identical values?
A: It is important to make sure that Quicksort does not degrade to O(n^2) on an array of identical values because we are wasting time and resources on an array that is technically already sorted. We can figure out if an array is filled with the same value by doing a quick O(n) traversal check before starting Quicksort.
No comments:
Post a Comment